 CETIS #54 “GUADALUPE VICTORIA”
CETIS #54 “GUADALUPE VICTORIA”
ALUMNAS:
ABIGAIL GUERRERO ARAIZA
EVELYN YAZBETH MORA ALVAREZ
6°F
PROFA. MARIA DE LOS ANGELES RUIZ
SANTIAGO




La desviación estándar es un índice numérico de la dispersión de un conjunto de datos (o población). Mientras mayor es la desviación estándar, mayor es la dispersión de la población. La desviación estándar es un promedio de las desviaciones individuales de cada observación con respecto a la media de una distribución. Así, la desviación estándar mide el grado de dispersión o variabilidad. En primer lugar, midiendo la diferencia entre cada valor del conjunto de datos y la media del conjunto de datos. Luego, sumando todas estas diferencias individuales para dar el total de todas las diferencias. Por último, dividiendo el resultado por el número total de observaciones (normalmente representado por la letra “n”) para llegar a un promedio de las distancias entre cada observación individual y la media. Este promedio de las distancias es la desviación estándar y de esta manera representa dispersión.
Matemáticamente, la desviación estándar podría, a primera vista, parecer algo complicada. Sin embargo, es en realidad un concepto extremadamente simple. En realidad no importa si usted no sabe calcular con exactitud la desviación estándar, siempre y cuando usted comprenda claramente el concepto. La desviación estándar es un indicador en extremo valioso con muchas aplicaciones. Por ejemplo, los estadísticos saben que cuando un conjunto de datos se distribuye de manera “normal”, el 68% de las observaciones de la distribución tiene un valor que se encuentra a menos de una desviación estándar de la media. También saben que el 96% de todas las observaciones tiene un valor no es mayor a la media más o menos dos desviaciones estándar (la Figura 18 grafica esta información). La desviación estándar de una población es normalmente representada por la letra griega (sigma), cuando se calcula sobre la base de toda la población; por la letra s (minúscula) cuando se infiere de una muestra; y por la letra S (mayúscula) cuando simplemente corresponde a la desviación estándar de una muestra. La fórmula de la desviación estándar es 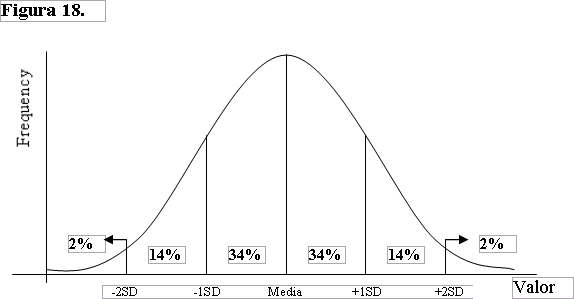 |
 .
.







| xi | fi | xi · fi | xi2 · fi | |
|---|---|---|---|---|
| [10, 20) | 15 | 1 | 15 | 225 |
| [20, 30) | 25 | 8 | 200 | 5000 |
| [30,40) | 35 | 10 | 350 | 12 250 |
| [40, 50) | 45 | 9 | 405 | 18 225 |
| [50, 60 | 55 | 8 | 440 | 24 200 |
| [60,70) | 65 | 4 | 260 | 16 900 |
| [70, 80) | 75 | 2 | 150 | 11 250 |
| 42 | 1 820 | 88 050 |





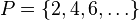

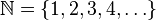





COEFICIENTE DE CORRELACIÓN
Frecuentemente denominado correlación. Una medida estadística ampliamente utilizada que mide el grado de relación lineal entre dos variables aleatorias. El coeficiente de correlación debe situarse en la banda de -1 a +1. El coeficiente de correlación se calcula dividiendo la covarianza de las dos variables aleatorias por el producto de las desviaciones típicas individuales de
las dos variables aleatorias
|
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}